Kubernetes zero downtime deployment: when theory meets the database
 Nicolas Fränkel
Nicolas FränkelIf you happen to use established online applications like e.g. Gmail, or some the biggest social media or e-commerce platforms, you probably never encountered a static page asking you “Please wait while we update our application”.
In fact, more and more services need to be always up and reachable for a variety of possible reasons:
- If none of your competitors has any downtime then you can’t afford it either. On the contrary, if your competitors have downtime, then your application always being available is a competitive advantage.
- Globally the user experience quality is rising, and users expect higher availability with time passing.
- If your application has a direct impact on your revenue e.g. a point-of-sales in the form of an e-commerce app - then you are probably already aware of the business impacts that downtime can cause.
While some accidental downtime is hard to avoid completely, updating one’s application with zero downtime is actually possible.

The ancestor: Blue-Green deployment
Probably one of the oldest ideas to achieve a zero downtime update is the Blue-Green deployment principle.
To sum it up, such principle states there should be two exactly similar environments, one referenced as Green, the other as Blue. At any point in time, one of them runs the production app, while the other runs the pre-production app. In front of them sits a dispatcher, which routes requests to the relevant environment: production or pre-production. When an update is required, you deploy it to the pre-production environment, test it, and switch the dispatcher so that pre-production becomes the new production environment, and vice versa.
Yet, there are several issues with the Blue-Green deployment:
The dispatcher that routes requests needs to have 0 latency.
Once the switch is made, environments are reversed, and users need to be routed to their environment. Depending on the dispatcher implementation - router, software proxy, etc. - it can be hard to achieve a zero-time switch.
What happens to users who happen to be already using the application when the switch is made?
The Grail of modern architectures is to achieve statelessness for obvious scalability issues. Yet, in real-life, state clings to not-so-dark corners of the application: have you ever tried to make a shopping cart stateless? The only way to handle this state is to migrate it from the the Blue to the Green environment when the switch is made. However, this does not happen instantly, and the users might find themselves in a in-between state, not fully in one environment, nor in the other.
What about the database?
As above, if there’s one Blue database and one Green database, data needs to be migrated from one to the other. It needs to be done ahead of time if possible, but since production data can change up until the switch, it’s also mandatory to do it just afterwards. And just as above, migration can take time and can block users in-between environments pending migration.
An obvious solution would be to move the database outside of the Blue-Green scope, sharing it to both environments. I won’t detail isolation issues introduced by this architecture, suffice to say they exist.
In addition, what if the database schema had to be updated for the new app version? A single shared database would require the schema changes to be compatible with the old app version. This in turn would prevent some changes for the sake of backward compatibility: it’s a sure way to accumulate of lot of technical debt, which will hunt you during the whole app lifecycle.
Kubernetes and rolling updates
Fortunately, Kubernetes allows to do without Blue-Green deployment, by providing a dedicated Deployment object.
A Deployment controller provides declarative updates for Pods and ReplicaSets.
You describe a desired state in a Deployment object, and the Deployment controller changes the actual state to the desired state at a controlled rate. You can define Deployments to create new ReplicaSets, or to remove existing Deployments and adopt all their resources with new Deployments.
The important bit in the description above is “at a controlled rate”: that means that a group of Pods can be updated one by one, two by two, by removing them all at once and spinning up new ones, the choice is yours. The exact behavior is configured by a snippet similar to this one:
apiVersion: apps/v1
kind: Deployment
spec:
replicas: 3
strategy:
rollingUpdate:
maxSurge: 0 # <2>
maxUnavailable: 1 # <3>
type: RollingUpdate # <1>
- Can be either
RecreateorRollingUpdate. In the first case, Kubernetes will terminate all the Pods, and then proceed to start the updated ones. This is great for a development environment, but doesn’t implement zero-downtime. Alternatively, the valueRollingUpdateconfigures Kubernetes to use themaxSurgeandmaxUnavailableparameter values. - Defines how many additional Pods can be started, compared to the number of
replicas. Can be a set number, or a percentage. - Defines how many Pods can be stopped from the current number of
replicas. Can be a set number, or a percentage.
Let’s illustrate the process with some examples.
The following diagrams show the evolution of the number of Pods, in regard to the version, as time passes.
- The vertical axis displays the number of Pods
- Blue represent the number of v1.0 Pods
- Dark blue represent the number of v2.0 Pods
- The horizontal axis displays the time
Deploy by adding a Pod, then remove an old one
In the first configuration, we allow a single additional Pod (maxSurge = 1) above the desired number of 3, and the number of available Pod cannot go below it (maxUnavailable = 0).

With this configuration, Kubernetes will spin up an additional Pod, then stop an “old” one down. If there’s another Node available to deploy this Pod, the system will be able to handle the same workload during deployment at the cost of extra infrastructure. Otherwise, the Pod will be deployed on an already used Node, and it will cannibalize resources from other Pods hosted on the same Node.
Deploy by removing a Pod, then add a new one
In the next example, we allow no additional Pod (maxSurge = 0) while allowing one single Pod at a time to be unavailable (maxUnavailable = 1).

In that case, Kubernetes will first stop a Pod before starting up a new one. The main benefit of this approach is that the infrastructure doesn’t need to scale up, keeping costs under constant control. On the downside, the maximum workload will be less.
Deploy by updating pods as fast as possible
Finally, the last configuration allows one additional Pod (maxSurge = 1) as well as one that is not available (maxUnavailable = 1), at any moment in time.

This configuration drastically reduce the time needed to switch between application versions, but combines the cons from both the previous ones.
Accounting for the time the application needs to start up
The time it takes for a newly started Pod to be able to handle a workload is not negligible unfortunately.
Yet, Kubernetes will send traffic to a newly started Pod as soon as it’s both **live ** and ready:
a live container means it’s running, while a ready container is able to serve requests.
By default, both hold the value Success.
This is an issue, because when the Pod is actually starting, the service will route requests to it, and it won’t respond.
To counter that, applications need to provide endpoints to be queried by Kubernetes that return the app’s status.
For example, imagine we developed a dedicated /ready endpoint, that returns an HTTP 200 status when it’s ready to handle requests, and HTTP 500 when it’s not.
Integrating the /ready endpoint with Kubernetes’ readiness probe can be achieved with the following snippet:
spec:
containers:
- name: foo-app
image: zerodowntime:1.0
readinessProbe:
httpGet:
path: /ready <2>
port: 8080 <3>
initialDelaySeconds: 10 <4>
periodSeconds: 2 <5>
- The path to the
/readyendpoint. This is the default as the Actuator defines it, but it can be changed. - The app’s port Again, this is Spring Boot’s default, but it can be overridden
- Time before the first check for readiness is done
- Time between two readiness checks after the first one
With the above configuration, Kubernetes will route traffic to a Pod only when the underlying app is able to handle it.
At this time, we know enough to handle “Hello World” types of applications. But rolling updates with Kubernetes face the same issue as Blue-Green deployment: changes need to be compatible database-wise!
Rolling updates and database schema compatibility: in detail
We mentioned above that schema changes must be backward compatible. Let’s illustrate the issue with a simple yet not trivial use-case.
Imagine the following database schema:

You may notice that this schema blurs the boundaries between a PERSON and an ADDRESS.
We should instead respects those boundaries, and target a schema like the following:
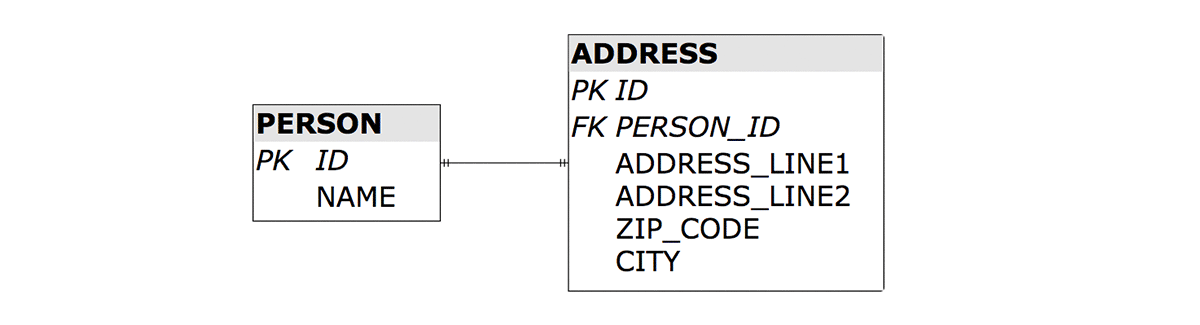
Let’s imagine the application using the original “blurred” schema is already in production, and is a huge success. Our goal is to transition to the final schema without any downtime.
We could design the new version of the application to be able to cope with the updated schema as well as the legacy one. This way, we could execute a rolling update deployment, then update the schema. This seems ideal, with one big caveat: the deployment cannot be rolled back, since the legacy application is not able to cope with the updated schema. Hence, application versions do not only need to be backward compatible, but forward compatible as well. It seems we’re back to square one, because the schema change cannot obviously be both.
To achieve our goal the trick is to split the schema update into a series of small side-by-side compatible schema updates. Additionally, the application needs to be updated in increments, such that a new app version is able to cope with the current schema update and the next one.
An important requirement is for the application to be the steering wheel behind schema changes. This can be done during app initialization.
With our example, here’s the migration path:
New application label is 2.1. Create the
ADDRESStable. For every change on thePERSONtable, mirror the change into this new table:Action on PERSONtableMirroring action on ADDRESStableINSERTINSERTduplicate data intoADDRESSUPDATECheck if an ADDRESSrecord already exists that references thePERSONrecord. If not, firstINSERTa newADDRESSrecord. In any case,UPDATEtheADDRESSrecord to duplicate thePERSONrecord data.DELETECheck if an ADDRESSrecord already exists that references thePERSONrecord. If yes, firstDELETEtheADDRESSrecord.This change is obviously forward compatible, because the app version 1.0 just ignores the
ADDRESStable.There are different ways to execute the mirroring action: if the database allows, it can be as simple as a trigger, otherwise, it can be done by the application.
Remember that in the former case, trigger creation should be done via the application.
New application label is 2.2. Move the source of truth from the
PERSONtable to theADDRESStable. For every change on theADDRESStable, mirror the change into thePERSONtable. This is the opposite to the table above.Regarding compatibility, app version 2.1 will still be using data in the
PERSONtable. It’s fine since its data mirrors theADDRESStable.Note that because some records might not have been updated through the application, an initialization job should take care of that accordingly.
New application label is 2.3. Let’s cleanup the schema to the final version by removing redundant columns from the
PERSONtable.This is again compatible, because app version 2.2 is using data from the
ADDRESStable.
Conclusion
While the idea behind rolling updates is quite simple, implementing it in real-life is not trivial: it’s all too easy to forget about deployment rollback.
And even if one takes it into account, then new requirements start to pop up, which make the development of an upgrade a task in its own right. Such is the cost of a zero-downtime architecture.
Now, while we have looked at the theoretical part of the article, you may be wondering how a real world implementation of the process would look like.
And that’s exactly what we cover in our followup, with a use-case on how to deploy a Spring Boot application on Kubernetes with zero downtime!



