The 9000-to-1500 cliff: an IPv6 PMTUD field note
 Victor Boglea
Victor BogleaHow a jumbo first hop, ECMP, and missing edge TCP MSS clamping turned healthy TCP handshakes into stalled transfers. A real MTU mismatch traced through ICMPv6 Packet Too Big behavior on Linux, anonymized from a dual-stack network.
The TCP handshake completed. The HTTP request left the host. The server ACKed it. Then the first large response stalled.
The route was present. The host firewall allowed ICMPv6 Packet Too Big. The first hop looked healthy. The real problem was subtler: a 9000-byte first hop feeding a 1500-byte path under IPv6, with ECMP and uneven PMTU learning in the mix.
Key terms in this article
- MTU mismatch — when the link MTU on one part of the path is larger than what subsequent links can carry. The classic example, and the one this article is about, is a 9000-byte first hop feeding a 1500-byte transit path.
- ICMPv6 Packet Too Big — the ICMPv6 message (Type 2, RFC 4443) a router sends when it has to drop an oversized IPv6 packet. The sole feedback mechanism for IPv6 PMTUD.
- TCP MSS clamping — rewriting the MSS option in TCP SYNs as they cross a network boundary, so endpoints negotiate a smaller segment size that fits the actual path. Often the most practical mitigation when PMTUD is fragile.
TL;DR
- A host can legitimately advertise a jumbo TCP MSS because its first-hop MTU is 9000, even when the real path MTU becomes 1500 a hop later.
- In IPv6, routers do not fragment in transit. Oversized packets are dropped, and the sender is informed with ICMPv6 Packet Too Big (PTB).
- The stall usually appears on the server → client direction, because the server honors the client’s oversized MSS advertisement.
- Under ECMP, PMTU is a property of the resolved path, not of the destination prefix. Different flows can land on different legs with different learned PMTUs.
- The most practical TCP mitigation is effective edge TCP MSS clamping, verified on the wire and not just in the config.
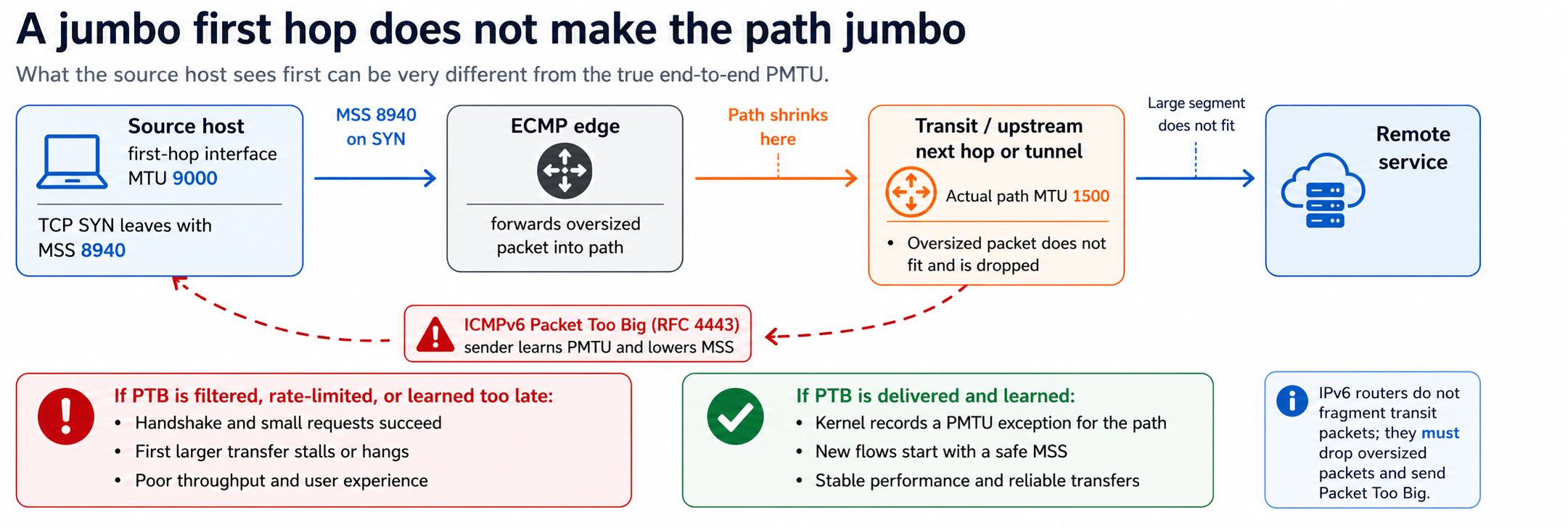
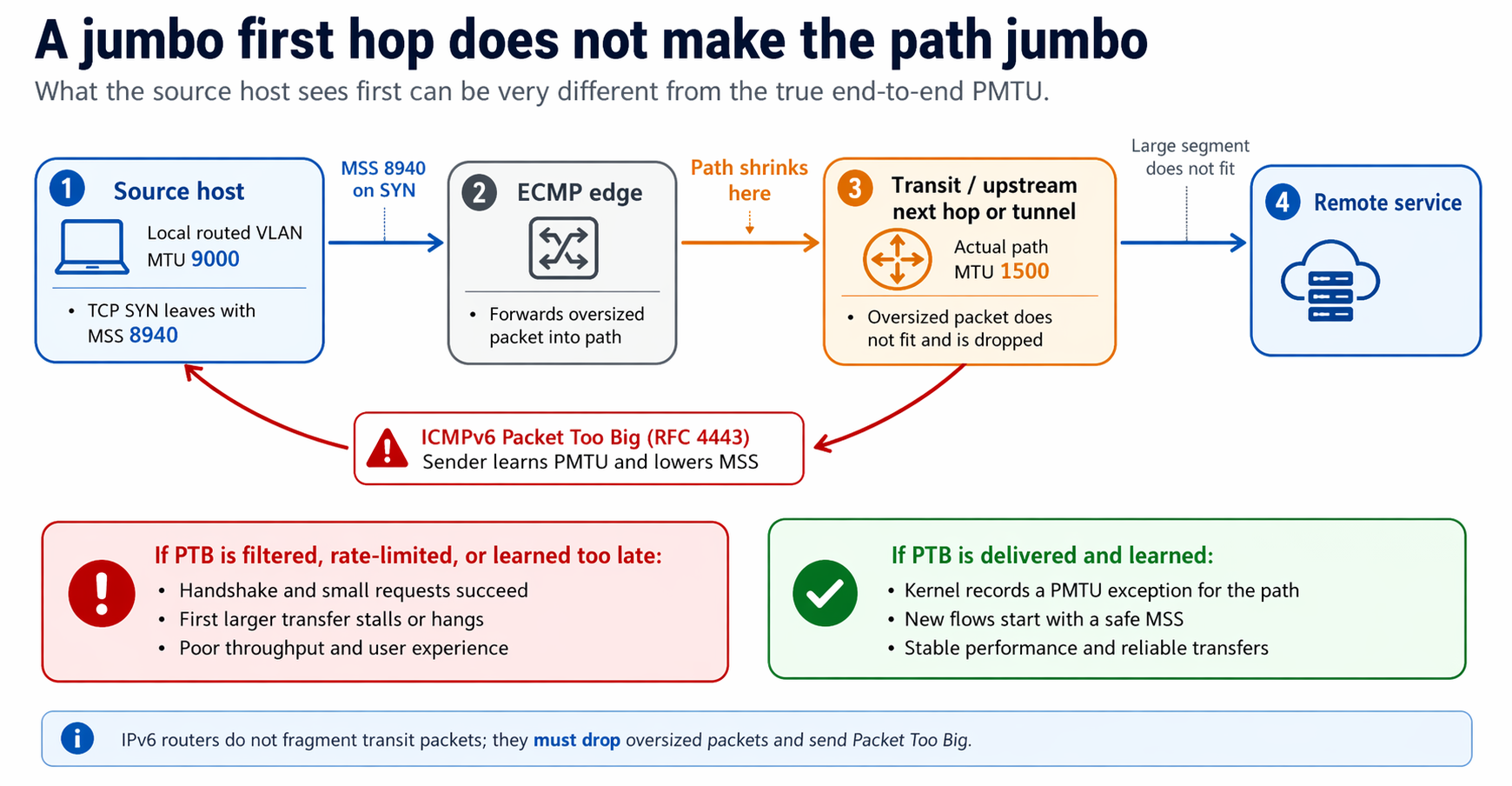
The setting
The environment was a dual-stack data center fabric carrying internal service-to-service traffic. Compute nodes had jumbo-enabled interfaces (MTU 9000) on the hypervisors. Upstream transit normalized to a standard 1500-byte MTU before traffic reached the remote zone. ECMP was in play on the path between zones. TCP was the dominant transport. The affected traffic was plain HTTP between internal services.
This matters because none of the components were wrong in isolation. The hypervisors were correctly configured for jumbo frames on their local interface. The transit path was correctly sized for the broader network. The ECMP fabric was correctly load-balancing. Each layer was doing exactly what it was configured to do. The MTU mismatch lived in the seam between them.
How it surfaced
The first signal was not dramatic. An internal service that periodically pulled configuration from a peer in another zone started reporting occasional timeouts. The request succeeded. The response hung. Retries sometimes worked and sometimes didn’t. Monitoring showed elevated TCP retransmits on the affected hosts but no packet loss on the network side. Small requests to the same destination worked fine, which made the problem look like an application-level issue at first.
Then someone noticed that responses under a certain size always worked and responses over it didn’t. That was the clue that turned the investigation from “intermittent bug in service X” into “something about this path drops large packets.”
MTU mismatch in IPv6: why it hurts more than in IPv4
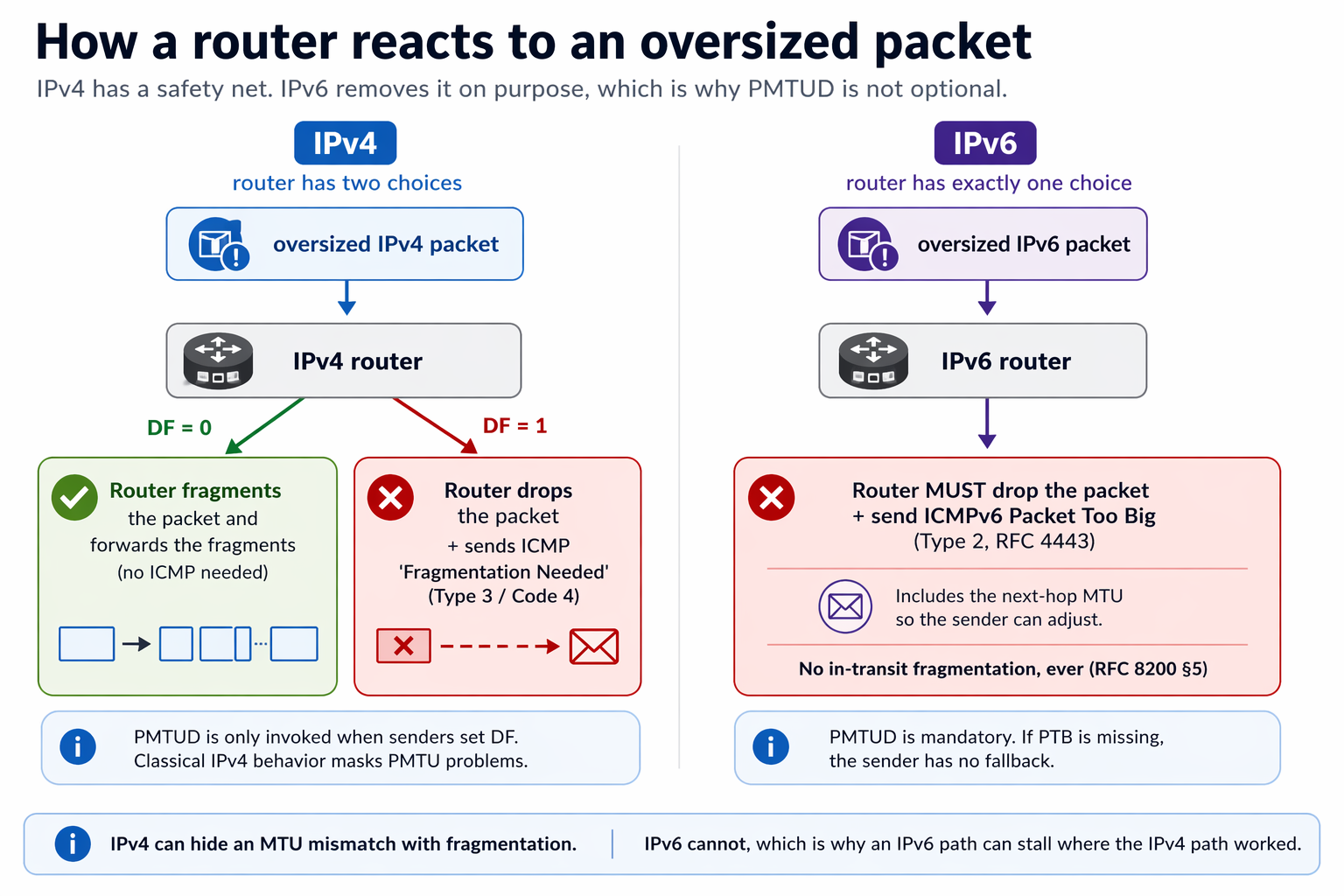
Both IPv4 and IPv6 support Path MTU Discovery, but they feel different to operate.
IPv4 has a safety net. If the Don’t Fragment bit is clear, routers are free to fragment a packet and forward it. Classical PMTUD only engages when senders set DF. In that case an oversized packet is dropped and an ICMP “fragmentation needed” (Type 3 / Code 4) comes back (RFC 1191).
Modern IPv4 TCP stacks set DF by default, so if the corresponding ICMP is blackholed, IPv4 will suffer the same stall. The real difference is at the protocol level. IPv4 still permits in-transit fragmentation as a fallback, so legacy middleboxes, misbehaving CPE, or ip_no_pmtu_disc=1 on a specific host can quietly keep traffic flowing despite broken PMTUD. IPv6 has no such escape hatch. RFC 8200 §5 forbids in-transit fragmentation entirely, so the 1500-byte cliff is absolute.
IPv6 removes that safety net by design. A router that cannot forward an oversized packet must drop it and must send an ICMPv6 Packet Too Big (Type 2, RFC 4443). That is the only available feedback mechanism.
The design is clean and standards-based, but it is unforgiving when the network underestimates how important those PTB messages are. A path can look healthy for small packets, complete the three-way handshake, and then stall only when real application data starts flowing (RFC 8201).
IPv6 is not broken here. It is simply more honest about path MTU.
The pattern that triggered the investigation
The symptom was the kind that makes on-call engineers reach for coffee:
- The source host had a 9000-byte MTU on its first-hop interface.
- Linux derived its outbound TCP MSS from that first-hop MTU, so SYNs left with an MSS of 8940.
- The SYN-ACK came back normally. SYNs are header-only and fit anywhere.
- A small HTTP request succeeded because it fit comfortably in one segment. The stall appeared on the server → client direction, because the server honored the client’s oversized MSS advertisement.
- The first large HTTP response failed. The server tried to send response segments sized to the client’s jumbo MSS, into a path that narrowed to 1500 bytes one hop later.
That last step is the whole story. The client’s advertised MSS sets the ceiling for server-to-client segments, not for client-to-server ones. In a jumbo-to-1500 scenario, the server is the one that crashes into the cliff.
A route lookup on the host told the story when the kernel had not yet learned the truth:
$ ip -6 route get 2001:db8:dead:beef::10
2001:db8:dead:beef::10 via 2001:db8:1::1 dev eth0 src 2001:db8:feed::123No PMTU exception visible. Linux behaved as if the first-hop MTU were the only fact that mattered.
Provoking a PTB event made the problem visible:
$ ping -6 -M do -s 8000 -c 1 2001:db8:dead:beef::10
PING 2001:db8:dead:beef::10(2001:db8:dead:beef::10) 8000 data bytes
ping: local error: message too long, mtu=1500
--- 2001:db8:dead:beef::10 ping statistics ---
1 packets transmitted, 0 received, +1 errors, 100% packet lossThat message too long, mtu=1500 is the kernel telling you it received a PTB and learned the real path MTU. After that event, the same lookup changed:
$ ip -6 route get 2001:db8:dead:beef::10
2001:db8:dead:beef::10 via 2001:db8:1::1 dev eth0 src 2001:db8:feed::123
expires 590sec mtu 1500The extra expires ... mtu 1500 line is the important clue. The kernel had learned a temporary PMTU exception for the resolved path.
ping -6 -M do -s <large> before trusting any host-side lookup. -M do prevents local fragmentation and forces the stack to send a single packet the network has to react to.The ECMP twist
This is where the debugging got interesting.
At the control-plane level, the base route looked like a normal multipath entry. But that is not the same object the kernel uses after it has resolved a particular flow. The ip-route(8) man page makes the distinction explicit:
ip route get fibmatchreturns the FIB-matched route- plain
ip route getreturns the resolved dst entry
Here is what we saw on the wire after provoking a PTB under ECMP:
# FIB view: shows the base multipath route, never any PMTU state
$ ip -6 route get fibmatch 2001:db8:dead:beef::10
2001:db8:dead:beef::/64 via 2001:db8:1::1 dev eth1 weight 1
via 2001:db8:1::2 dev eth2 weight 1
# Resolved view: shows a specific nexthop, but no PMTU exception
$ ip -6 route get 2001:db8:dead:beef::10
2001:db8:dead:beef::10 via 2001:db8:1::2 dev eth2 src 2001:db8:feed::123
# ^^^ no "expires ... mtu 1500", even though PTB was received moments agoThat was the confusing part. We had just provoked a PTB. The kernel acknowledged it with message too long, mtu=1500. But neither fibmatch nor plain get showed any PMTU exception. On IPv4, the same test would have shown cache expires ... mtu 1500 immediately.
The exception existed. It was just invisible to the lookup. Understanding why requires the next section. Other stacks store this state differently, but the underlying protocol point is the same: PMTU belongs to a path, not a prefix. IPv6 ECMP hashing on Linux can also include the IPv6 flow label. Automatic flow labels are enabled by default (net.ipv6.auto_flowlabels=1) and flow-label participation in ECMP is controlled by net.ipv6.fib_multipath_hash_policy (see the Linux IP sysctl documentation). That means two otherwise similar IPv6 flows can pick different ECMP legs, and a later ad-hoc lookup may not be inspecting the same resolved path that just learned the exception.
PMTU is, by definition, a property of a path, not of a destination prefix. That is not a Linux quirk. It is how the protocol is defined. It means an ECMP fabric with uneven effective MTUs will produce troubleshooting artifacts that feel inconsistent unless you know where PMTU state actually lives.
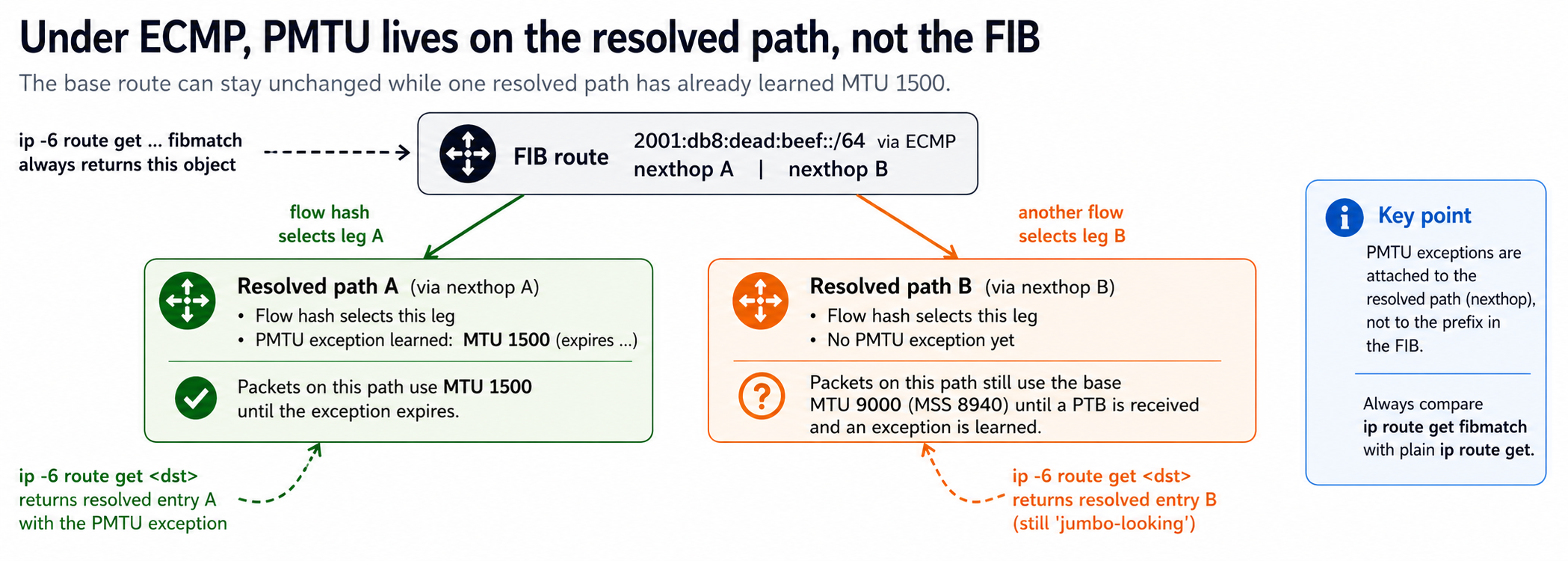
mtu 1500 exception and another has not.The real asymmetry: how Linux stores PMTU under ECMP
If your mental model comes from IPv4, this is where it breaks. And it breaks silently.
On IPv4, the standard diagnostic works on modern kernels. Provoke the event with ping -M do -s <large>, then inspect the kernel’s cached PMTU with ip route get <dst>. You see mtu <smaller> immediately, regardless of which ECMP leg the lookup lands on. On IPv6, the same sequence may show no exception at all.
Here is the difference on the wire:
# ---- IPv4 under ECMP ----
$ ping -M do -s 8000 -c 1 198.51.100.10
PING 198.51.100.10 (198.51.100.10) 8000(8028) bytes of data.
ping: local error: message too long, mtu=1500
$ ip route get 198.51.100.10
198.51.100.10 via 10.0.1.1 dev eth0 src 10.0.0.5
cache expires 580sec mtu 1500
# ^^^ visible immediately, even if this lookup hashed to a different leg
# ---- IPv6 under ECMP (no pin) ----
$ ping -6 -M do -s 8000 -c 1 2001:db8:dead:beef::10
PING 2001:db8:dead:beef::10(...) 8000 data bytes
ping: local error: message too long, mtu=1500
$ ip -6 route get 2001:db8:dead:beef::10
2001:db8:dead:beef::10 via 2001:db8:1::2 dev eth2 src 2001:db8:feed::123
# ^^^ no mtu line; this lookup resolved to a different fib6_nh
# ---- IPv6 under ECMP (pinned with /128) ----
$ ip -6 route add 2001:db8:dead:beef::10/128 via 2001:db8:1::1
$ ping -6 -M do -s 8000 -c 1 2001:db8:dead:beef::10
ping: local error: message too long, mtu=1500
$ ip -6 route get 2001:db8:dead:beef::10
2001:db8:dead:beef::10 via 2001:db8:1::1 dev eth1 src 2001:db8:feed::123
expires 590sec mtu 1500
# ^^^ now visible: ping and lookup forced onto the same fib6_nhThat three-way comparison is the core of the asymmetry. IPv4 shows the exception everywhere. IPv6 shows it only on the nexthop that learned it.
A useful way to picture it is to imagine an ECMP route with four nexthops, A through D. A single PTB arrives:
With IPv4:
One ICMP "Frag Needed" says: path MTU = 1500
Linux IPv4 then records:
nexthop A -> mtu 1500
nexthop B -> mtu 1500
nexthop C -> mtu 1500
nexthop D -> mtu 1500
With IPv6:
One ICMPv6 Packet Too Big says: path MTU = 1500
Linux IPv6 records only:
selected nexthop B -> mtu 1500
Other nexthops still have no PMTU exception:
nexthop A -> no learned mtu
nexthop C -> no learned mtu
nexthop D -> no learned mtuThat picture is the whole story. The mechanism behind it is in the kernel.
Where the exception is stored. On current Linux IPv6, PMTU exceptions are attached to the selected nexthop object (struct fib6_nh), in its per-nexthop exception bucket. They are not propagated to the other nexthops in the ECMP group. A later lookup that resolves to a different nexthop for the same prefix has nothing cached, even though the exception exists.
Current Linux IPv4 behaves differently on exactly this point. When __ip_rt_update_pmtu() runs and the matched route is multipath, the kernel explicitly iterates over every nexthop in that route and calls update_or_create_fnhe() for each. A single PTB event installs the exception across all legs, so the subsequent lookup sees mtu <smaller> whether or not it hashed to the same leg as the ping. (Older IPv4 kernels did not do this propagation, so on a pre-propagation kernel, IPv4 would behave closer to how IPv6 behaves today.)
This asymmetry is in the PMTU update path itself, not in the ECMP hashing logic. No sysctl flips the IPv6 behavior to match IPv4. Even if you set fib_multipath_hash_policy identically on both stacks, the storage difference remains. The hash policy decides which nexthop a flow uses; it does not control how a learned PMTU is recorded after the kernel sees a PTB.
Hash policy as a secondary effect. ECMP hashing can compound the visibility problem if the hash policies differ between stacks. With the default fib_multipath_hash_policy=0, IPv6 includes the flow label in the hash and IPv4 does not. Combined with net.ipv6.auto_flowlabels=1, the ping6 socket hashes one way and a subsequent ip -6 route get (with no flow label) hashes another way, so they can resolve to different nexthops even with otherwise-identical inputs. With fib_multipath_hash_policy=1 on both stacks (L4, standard 5-tuple), the flow label is no longer in play and a tuple-aware lookup will reproduce the same hash a real connection took. Either way, the storage asymmetry above is the dominant cause of the visibility difference.
The protocol rule has not changed. PMTU belongs to a path, not a prefix. Linux just surfaces that rule differently for IPv6 and IPv4 under multipath today.
ip -6 route get <dst> does not reproduce the hash of a real TCP connection. For L4-policy ECMP, supply the full tuple: ip -6 route get <dst> from <src> ipproto tcp sport <X> dport <Y>. That is closer to the path the kernel will actually pick for a real flow, and it is the right command to use when you are trying to reproduce what a specific TCP connection saw.The cleanest way to prove the mechanism to yourself, or to a skeptical colleague, is to pin the destination. Add a /128 static route for the specific destination via a specific nexthop. ECMP collapses for that prefix. The ping and the subsequent ip -6 route get are forced onto the same fib6_nh, and expires ... mtu 1500 appears immediately in plain ip -6 route get. If you see it with the pin and not without, you have just proven the per-nexthop storage. Not an absence of PMTU learning.
This is the single biggest reason IPv6 path-MTU debugging feels flaky to engineers with deep IPv4 experience. Your tools are not broken. They are answering a subtly different question than they did on IPv4: about where the kernel stores what it learned, and on default-policy systems, also about which nexthop a fresh lookup picks.
Why one zone worked and another did not
The most useful comparison in our case was between two otherwise similar zones.
- In both zones, the source host had a jumbo first hop.
- In both zones, the path to the destination dropped to 1500 very early.
- In both zones, small packets and handshakes were fine.
But only one zone behaved consistently well for TCP.
The difference was at the edge.
In the working zone, TCP MSS clamping was effective on the egress path. The host could still originate a SYN with its jumbo-derived MSS, but the edge device rewrote the MSS option in the outbound SYN before it left the zone. That outbound rewrite is the causally important one. The client’s advertised MSS is the ceiling for what the server sends back, so clamping it down forces the server to use a safe segment size from the first response onward. TCP no longer depends on PMTUD converging in time. (A complete implementation also clamps the return SYN-ACK, which bounds the client-to-server direction, but in a jumbo-to-1500 scenario that direction was never the bottleneck.)
In the failing zone, the intended MSS clamping was either absent, ineffective on the actual egress path, or applied in the control plane but not in hardware on the correct forwarding ASIC. TCP became dependent on PMTUD converging quickly enough, and that made the behavior intermittent.
The key point is that MSS clamping masks the PMTUD problem for TCP. UDP-based transports such as QUIC, along with ESP and fragmented UDP traffic, stay outside the protection that TCP MSS clamping provides. But for TCP, clamping often turns a fragile path into a working one.
What we actually did: edge TCP MSS clamping in practice
The fix was unglamorous, which is how most real fixes are.
We confirmed on the wire that the SYN leaving the host in the failing zone carried mss 8940, and that the SYN arriving on the other side of the edge also carried mss 8940. That told us the clamp in the failing zone was not taking effect on the egress path, despite being present in the configuration. Investigation on the edge device showed the clamping rule was attached to the wrong forwarding context. It matched traffic on the control plane but was not in the data-plane path that traffic actually took.
Moving the clamp to the correct egress rule, the one that matched the real forwarding path for cross-zone traffic, took effect within minutes. A follow-up capture confirmed the SYN leaving the edge now carried mss 1396. (We clamp to 1396 rather than the textbook 1440 because our path includes encapsulation overhead: 1500 minus the 40-byte IPv6 header, the 20-byte TCP header, and a 44-byte allowance for tunnels and overlay encapsulation in the path.) Subsequent response stalls disappeared, and the service that originally reported the timeouts returned to normal behavior without a restart.
That handled the bulk of the problem. We then ran into a more interesting follow-on.
For most traffic, the IPv6 MSS clamp on the edge worked exactly like its IPv4 counterpart. But there was an edge case where the IPv4 clamp applied cleanly and the IPv6 clamp did not, on the same device, with what looked like equivalent configuration. We verified the same scenario on a different edge platform in a comparable role and the IPv6 clamp behaved correctly there. That makes the asymmetry platform-specific rather than something inherent to IPv6 MSS clamping. We are working with the platform vendor to determine whether this is a software bug or a documented limitation. Until we have a confirmed answer, the operational lesson is the safer one: do not assume an IPv4 MSS clamp implementation transfers cleanly to IPv6 on the same device. Verify both stacks on the wire.
The entire functional fix was one configuration change on one device. The debugging work that led up to it — distinguishing first-hop MTU from path MTU, tracing PMTU learning on the kernel, proving the per-nexthop exception storage under ECMP, capturing on both sides of the edge, comparing IPv4 and IPv6 clamp behavior on the same platform — was most of the week.
“But the host-side capture still showed MSS 8940”
This is an easy trap.
A capture taken on the source host shows the SYN before any edge rewriting. It is perfectly normal to see MSS 8940 in the host-side capture even when edge MSS clamping is working downstream.
To actually verify MSS clamping, you need at least one of:
- a capture after the egress router or firewall
- a capture on the remote side
- vendor counters or platform-specific verification that the rewrite is happening in hardware on the correct egress interface
That distinction turned out to be crucial. Host captures proved what Linux originated. They did not prove what the edge finally transmitted.
The method matters less than the location. Use whatever capture tool fits your environment: tcpdump, Wireshark, a vendor packet capture utility, or an inline tap. The question to answer is simple: what MSS value appears in the SYN as it leaves the edge?
- If the SYN leaving the edge still carries
mss 8940, the clamp is not taking effect on the egress path, regardless of what the configuration says. - If it carries the clamped value (
mss 1396in our case, ormss 1440in a path with no encapsulation overhead), the rewrite is working and the server will use that value for the entire connection.
A host-side capture showing mss 8940 is expected and normal. That is what Linux originated. It does not tell you what the edge transmitted.
Practical design lessons
1) Do not confuse first-hop MTU with path MTU
A 9000-byte interface on the hypervisor does not imply a 9000-byte end-to-end path. If the path drops to 1500 after the first hop, the source must either learn that PMTU through PTB, or be prevented from starting with an oversized TCP MSS.
2) Treat ICMPv6 Packet Too Big as infrastructure, not optional
IPv6 PMTUD depends on PTB. RFC 4890 explicitly states that PTB must not be filtered by firewalls. This is not a soft recommendation. If those messages are filtered, aggressively rate-limited, or lost inside tunnels or ECMP asymmetry, application behavior becomes misleadingly partial: handshakes succeed, small exchanges work, and real transfers stall.
A frequent and under-appreciated culprit is a stateful firewall in front of the receiver. For the PTB to be useful, the firewall has to inspect the embedded original packet inside the ICMPv6 error and correlate it with an existing TCP flow. Many firewalls do not do that correlation by default and simply drop the “unsolicited” ICMPv6 error. The sender never learns the real path MTU and hangs, waiting for ACKs that will never come.
3) Normalize effective MTU across ECMP legs
PMTU is path-specific. If one ECMP leg behaves as jumbo and another behaves as 1500, the network is teaching the host two different truths. Even if the destination prefix is the same, the forwarding behavior is not.
4) Use edge MSS clamping as a pragmatic TCP mitigation
At the network edge, MSS clamping can keep TCP inside a safe segment size from the first SYN onward. This is especially helpful when the first hop is jumbo, the real path is not, the path contains tunnels or encapsulation overhead, or you cannot guarantee perfect PMTUD behavior everywhere.
This is an operational mitigation, not a substitute for sound PMTUD.
5) Consider PLPMTUD and host-side resilience
Where appropriate, Packetization Layer PMTUD (PLPMTUD, RFC 4821) reduces reliance on classic ICMP-driven discovery. Its datagram variant (DPLPMTUD, RFC 8899) is what modern QUIC stacks use. On Linux, tcp_mtu_probing can also help TCP recover from PMTUD black holes.
6) Validate on the wire, not just in config
A line in a router configuration does not prove that the packet was rewritten in the path you care about. For MSS clamping in particular, verify:
- the traffic is routed out the intended interface
- the feature is supported in the actual forwarding path, not just the control plane
- the rewritten SYN on egress shows the expected value
7) Verify IPv4 and IPv6 MSS clamping separately
These are two different code paths inside most edge platforms, even when they share a common configuration syntax. We have observed an edge case where an IPv4 MSS clamp applied cleanly and the IPv6 equivalent did not, on the same device, with what looked like the same configuration. The same scenario worked correctly on a different vendor’s platform, which makes the gap platform-specific rather than inherent to IPv6.
The practical implication: a successful IPv4 clamp test tells you nothing about the IPv6 clamp. Capture both stacks separately, on the actual egress path, and confirm each one shows the expected MSS value. Treat IPv6 clamping as its own feature with its own verification, not as a free side-effect of the IPv4 implementation.
A compact troubleshooting workflow
When a dual-stack path looks healthy in IPv4 but fragile in IPv6, this workflow has paid for itself more than once:
- Trace the path MTU, not just the path. Tools like
scamper -c "trace -M"are invaluable. - Provoke a PTB event with
ping -6 -M do -s <large>and check whether the kernel learnsexpires ... mtu ...onip -6 route get. - Separate FIB view from resolved-path view. Use both
ip -6 route get fibmatchand plainip -6 route get, and remember what each one means. Under L4-policy ECMP (fib_multipath_hash_policy=1), a tuple-less lookup will not hash like a real TCP flow. Supply the tuple to reproduce the real path:ip -6 route get <dst> from <src> ipproto tcp sport <X> dport <Y>. - If ECMP is in play, pin the destination. Add a
/128static route via a specific nexthop and repeat steps 2 and 3. Ifexpires ... mtu 1500appears only with the pin, you have per-nexthop PMTU storage and/or flow-label hash divergence, not missing PMTU learning. - Capture on both sides of the edge if you suspect MSS clamping. Host captures prove what Linux originated. They do not prove what the edge transmitted.
- Check the local policy last, not first. A host firewall can allow ICMPv6 PTB and the problem can still be elsewhere in the path.
The broader lesson
The point of this field note is not that IPv6 is fragile and IPv4 is fine.
The point is that IPv6 makes path-MTU truth impossible to ignore.
That is usually a good thing. It forces networks to be explicit about encapsulation overhead, ECMP symmetry, control-plane vs. data-plane parity, and the difference between a local interface MTU and the real end-to-end path.
In our case, the design lesson was simple:
If your first hop is jumbo and your real path is not, treat PMTUD and MSS clamping as first-class design concerns, not last-minute mitigations.
That is not an IPv6 bug. It is what designing for IPv6 at scale actually looks like.
References
- RFC 1191 — Path MTU Discovery (Mogul, Deering)
- RFC 4443 — ICMPv6 (Conta et al.)
- RFC 4821 — Packetization Layer Path MTU Discovery (Mathis, Heffner)
- RFC 4890 — Recommendations for Filtering ICMPv6 Messages in Firewalls (Davies, Mohacsi)
- RFC 8200 — Internet Protocol, Version 6 (IPv6) Specification (Deering, Hinden)
- RFC 8201 — Path MTU Discovery for IP version 6 (Hinden, McCann)
- RFC 8899 — Packetization Layer Path MTU Discovery for Datagram Transports (Fairhurst et al.)
- ip-route(8) — Linux manual page
- Linux IP sysctl documentation

